SLAM is simultaneous localization and mapping; the goal is to build/update a map while simultaneously keeping track of location within.
In other words, SLAM takes sensory data as input (such as camera, lidar, ultrasound) and outputs a partial map and location within.
A popular open source framework is called ORB SLAM. This is fast, robust, and efficient.
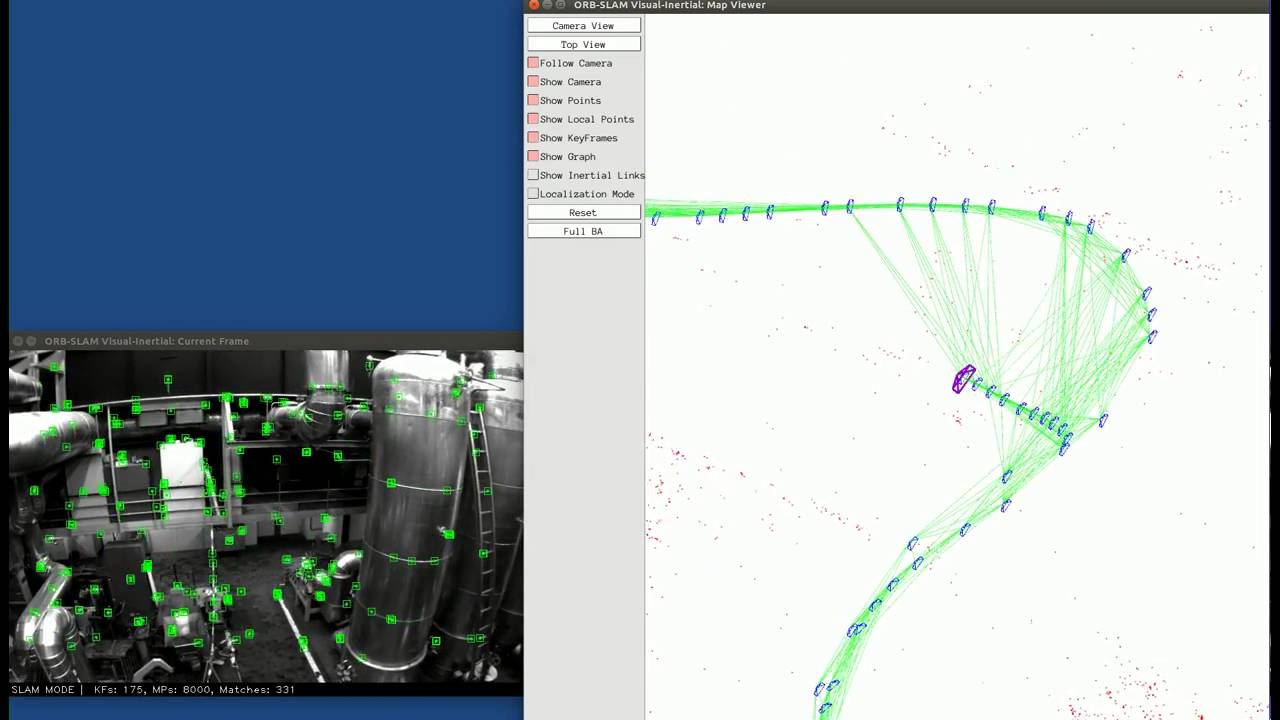 I’ll summarize my findings here.
I’ll summarize my findings here.
There are three papers you can read that describes how it works. You should read them in order, because the ideas build on each other (1-2) and (3) describe improvements made.
1. Bag of Binary Words
2. ORB-SLAM paper
3. ORB-SLAM2 paper
I’m not much of an expert in this field, so I’ll try to explain in layman’s terms of how I understand it. Here are essence of what you need to know.
- Sensory data are a stream, but it can be discretized, such as a video stream.
- Discrete means to represent a real space using a discrete quantities.
- Videos are sequences of images.
- In an image, there are points that can be easily identified and tracked across images.
- These points can be identified by an algorithm called Bag of Words (read 1).
- A picture is like a paragraph, it can be described by visual words.
- Visual words are small images that represent like noses, eyes, mouth.
- With enough words, you can guess what objects you’re looking at, and from what angle.
- For example, if you had two eyes and a nose, you would guess a face.
- And if the two eyes are much bigger than the nose, you’re likely looking downward angle to the face.
- Bag of Binary Words improve performances of the Bag of Words (BoW) model.
- The ORB-SLAM system uses the BoW model to build a database.
- Database stores BoW features that represent an image.
- Meaning the image was converted into BoW features.
- These features are used as an index into a location map.
- Database stores BoW features that represent an image.
- From an image and a location, a Key Frame can be created.
- Key Frames are an association container, which can represent a mapping of BoW features into a frame in location space, and vice versa.
- Using these BoW features, and sensor calibration data, a location is triangulated from mathematical calculation.
- Many of these Key Frames are linked together.
- You can think of Key Frames being a vertex in a graph, and an edge represent co-visibility.
- That is, the BoW feature is visible from the other Key Frame as well.
- This graph is called a covisibility graph.
- Which represents a map.
- You can think of Key Frames being a vertex in a graph, and an edge represent co-visibility.
- Having this graph aids in knowing when to insert a new Key Frame into the database.
- For example, when two Key Frames have less than 75% common BoW features.
- When given an image, the database is asked to return a list of plausible locations.
- The image is converted into BoW feature.
- This feature is used to search the covisibility graph to find similar Key Frames.
- Returns a list of Key Frames with statistical likelihood to represent which Key Frames contains the most matched BoW features.
- The covisibility graph reduces search complexity, therefore speeding up search, and also reduces storage needs.
- So now a map is being built at the same time it is localized.
- SLAM.
- In the future, we can come back with more data to:
- Improve the map.
- Ask the database for a localization result.
That’s all folks. I’ll add some pictures later.
Here’s a video.