Recently I made a website for Sophie (smoosophie.com) and scraped her blog from QQ’s QZone.
QQ has an API that can be used for QZone, but it is hard to develop for. Mainly the API is poorly documented and hard to use for a native English speaker. Although I could read Chinese (slowly), reading professional terms is something I have to work on.
Workflow screenshots
Anyhow, I decided to practice javascript and manually scrape it. Here are the steps I took:
This is what the QZone page looks like.
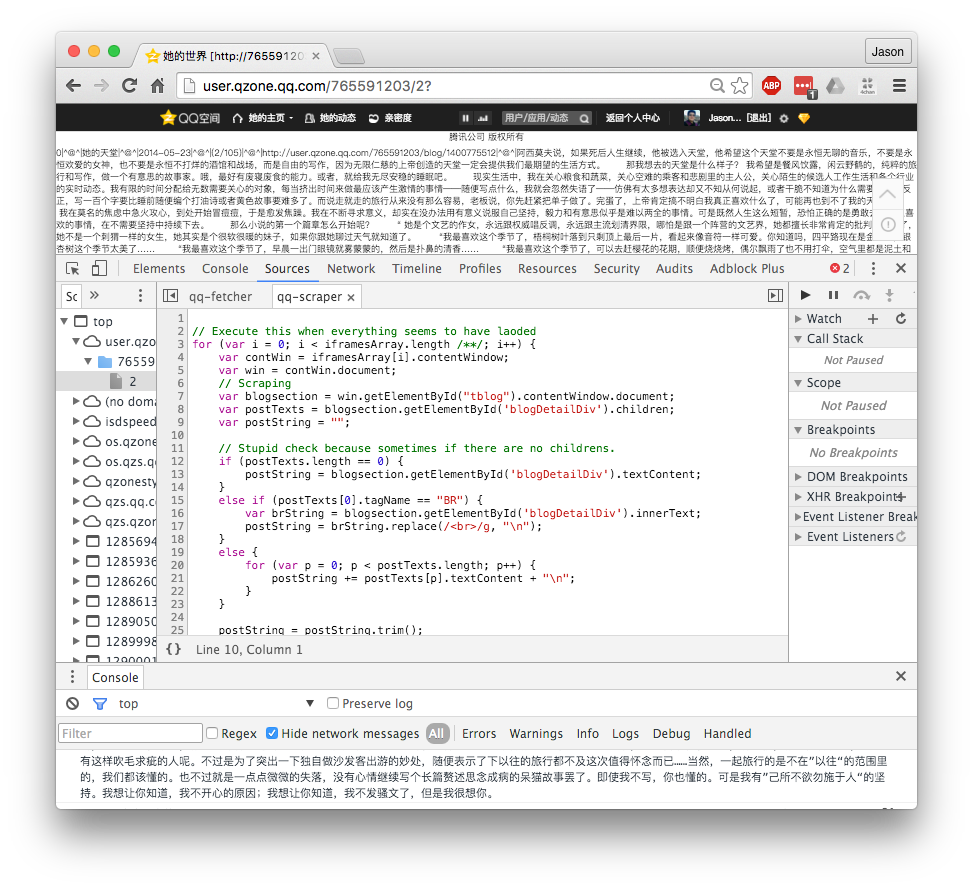
This is running the fetching script.
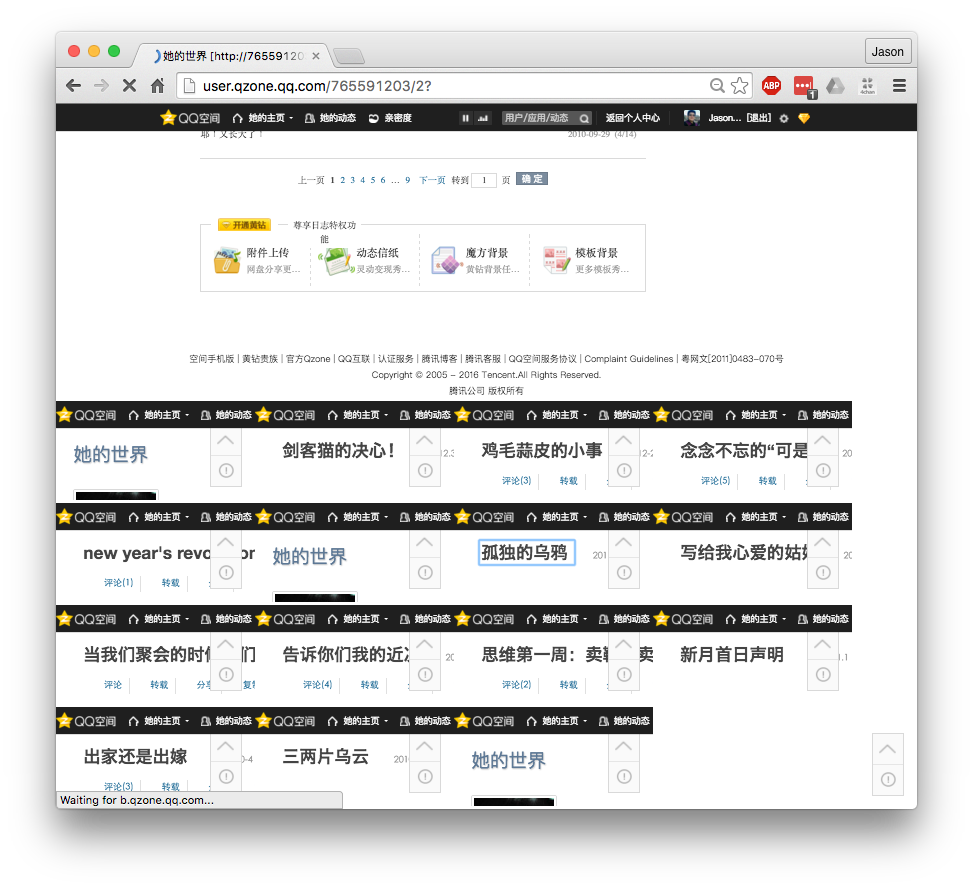
After running the fetching script, it all of the blog links as individual iframes onto the page. Because these loads are network requests, I manually wait until all of them are loaded. The javascript console will stop scrolling and printing things if they’ve all completely loaded.
Here are all the frames after being loaded. Then I run the scraper javascript, and it scrapes the iframe for their blog content and post them to the current screen.
I manually copy paste them into csv files.
This is the first line of a csv entry.
![]()
Then I wrote a ruby script to add these csv to a wordpress blog.
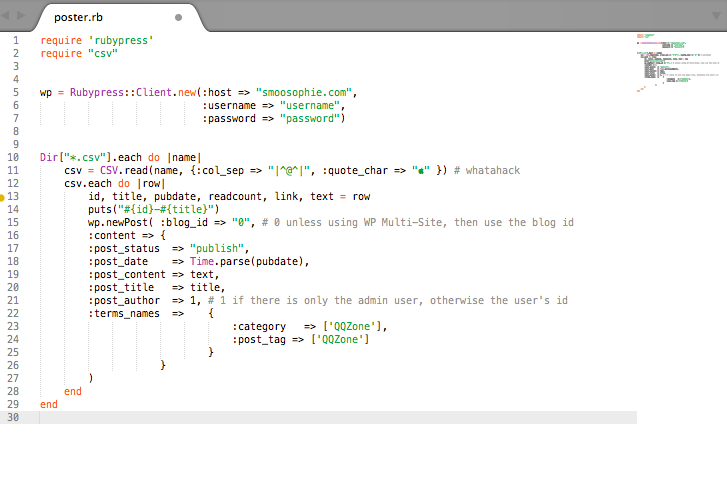
Here’s what running it looks like.

Source code
Run the fetcher.js on the blog page.
// fetcher.js
// Javascript to paste into chrome console to fetch the posts.
var ul = document.createElement("UL") // Create a <ul> node
ul.setAttribute("id", "myList")
document.body.appendChild(ul);
var s = "|^@^|"; // seperator
var iframesArray = [];
var messagesArray = [];
var posts = document.getElementById("tblog").contentWindow.document.getElementById("listArea").getElementsByTagName("li")
for (var i = 0; i < posts.length /**/; i++) {
var postTitle = posts[i].getElementsByClassName("article")[0].textContent;
var postLink = posts[i].getElementsByClassName("article")[0].getElementsByTagName("a")[0].href
// http://user.qzone.qq.com/765591203/blog/1400775512
var entryDate = posts[i].getElementsByClassName("list_op")[0].childNodes[0].textContent;
var readCount = posts[i].getElementsByClassName("list_op")[0].childNodes[2].textContent;
var message = i +s+ postTitle +s+ entryDate +s+ readCount +s+ postLink +s;
messagesArray.push(message);
var iframe = document.createElement('iframe')
iframe.src = postLink;
document.body.appendChild(iframe)
iframesArray.push(iframe);
}
After you manually determine the time to wait, run this to scrape all the iframes and add to the current html. There you can copy paste into a csv file.
// scraper.js
// Execute this when everything seems to have laoded
for (var i = 0; i < iframesArray.length /**/; i++) {
var contWin = iframesArray[i].contentWindow;
var win = contWin.document;
// Scraping
var blogsection = win.getElementById("tblog").contentWindow.document;
var postTexts = blogsection.getElementById('blogDetailDiv').children;
var postString = "";
// Stupid check because sometimes if there are no childrens.
if (postTexts.length == 0) {
postString = blogsection.getElementById('blogDetailDiv').innerHTML;
}
else if (postTexts[0].tagName == "BR") {
var brString = blogsection.getElementById('blogDetailDiv').innerHTML;
postString = brString; // .replace(/<br>/g, "\n")
}
else {
for (var p = 0; p < postTexts.length; p++) {
postString += "<p>" + postTexts[p].innerHTML + "\n </p>";
}
}
postString = postString.trim();
if (postString.length == 0) {
postString = "ERROR parsing!";
}
var message = messagesArray[i] + postString;
console.log(message)
var node = document.createElement("LI") // Create a <li> node
var textnode = document.createTextNode(message) // Create a text node
node.appendChild(textnode) // Append the text to <li>
document.getElementById("myList").appendChild(node) // Append <li> to <ul> with id="myList"
// document.body.removeChild(iframe)
// win.body.parentNode.removeChild(win.body)
}
Once the csv files are created, post it to the wordpress blog.
#poster.rb
require 'rubypress'
require "csv"
require 'sanitize'
wp = Rubypress::Client.new(:host => "smoosophie.com",
:username => "sophie",
:password => "1Smoosophie!",
# :use_ssl => true,
:retry_timeouts => true)
Dir["*.csv"].each do |name|
puts "============= #{name} ============="
csv = CSV.read(name, {:col_sep => "|^@^|", :quote_char => "" }) # whatahack
csv.each do |row|
id, title, pubdate, readcount, link, text = row
cleantext = Sanitize.clean(text, :elements => ['br','p', 'a'])
puts("#{id}-#{title}")
# puts("#id #{id}, title #{title}, pubdate #{pubdate}, readcount #{readcount}, link #{link}, text #{text}")
begin
retries ||= 0
puts "try ##{ retries }"
sleep(1)
wp.newPost( :blog_id => "0", # 0 unless using WP Multi-Site, then use the blog id
:content => {
:post_status => "publish",
:post_date => Time.parse(pubdate),
:post_content => cleantext,
:post_title => title,
:post_author => 1, # 1 if there only is admin user, otherwise user's id
:terms_names => {:category => ['QQZone'], :post_tag => ['QQZone'] }
}
)
rescue
retry if (retries += 1) < 3
end
end
end